pYAAPT¶
This a ported version for Python from the YAAPT (Yet Another Algorithm for Pitch Tracking) algorithm. The original MATLAB program was written by Hongbing Hu and Stephen A. Zahorian.
The YAAPT program, designed for fundamental frequency tracking, is extremely robust for both high quality and telephone speech. The YAAPT program was created by the Speech Communication Laboratory of the state university of New York at Binghamton. The original program is available at http://www.ws.binghamton.edu/zahorian as free software. Further information about the program could be found at [ref1].
It must be noticed that, although this ported version is almost equal to the original, some few changes were made in order to make the program more “pythonic” and improve its performance. Nevertheless, the results obtained with both algorithms were similar.
Quick start¶
The pYAAPT basically contains the whole set of functions to extract the pitch track from a speech signal. These functions, in their turn, are independent from the pyQHM package. Therefore, pYAAPT can be used in any other speech processing application, not only in the AM-FM decomposition.
USAGE:
- amfm_decompy.pYAAPT.yaapt(signal[, options])¶
- Parameters:
signal (signal object) – created with amfm_decompy.basic_tools.
options (Must be formatted as follow: **{‘option_name1’ : value1, ‘option_name2’ : value2, …}) – the default configuration values for all of them are the same as in the original version. A short description about them is presented in the next subitem. For more information about them, please refer to [ref1].
- Return type:
pitch object
OPTIONS:
‘frame_length’ - length of each analysis frame (default: 35 ms)
‘tda_frame_length’ - frame length employed in the time domain analysis (default: 35 ms). IMPORTANT: in the original YAAPT v4.0 MATLAB source code this parameter is called ‘frame_lengtht’. Since its name is quite similar to ‘frame_length’, the alternative alias ‘tda_frame_length’ is employed by pYAAPT in order to avoid confusion. Nevertheless, both inputs (‘frame_lengtht’ and ‘tda_frame_length’) are accepted by the yaapt function.
‘frame_space’ - spacing between analysis frames (default: 10 ms)
‘f0_min’ - minimum pitch searched (default: 60 Hz)
‘f0_max’ - maximum pitch searched (default: 400 Hz)
‘fft_length’ - FFT length (default: 8192 samples)
‘bp_forder’ - order of band-pass filter (default: 150)
‘bp_low’ - low frequency of filter passband (default: 50 Hz)
‘bp_high’ - high frequency of filter passband (default: 1500 Hz)
‘nlfer_thresh1’ - NLFER (Normalized Low Frequency Energy Ratio) boundary for voiced/unvoiced decisions (default: 0.75)
‘nlfer_thresh2’ - threshold for NLFER definitely unvoiced (default: 0.1)
‘shc_numharms’ - number of harmonics in SHC (Spectral Harmonics Correlation) calculation (default: 3)
‘shc_window’ - SHC window length (default: 40 Hz)
‘shc_maxpeaks’ - maximum number of SHC peaks to be found (default: 4)
‘shc_pwidth’ - window width in SHC peak picking (default: 50 Hz)
‘shc_thresh1’ - threshold 1 for SHC peak picking (default: 5)
‘shc_thresh2’ - threshold 2 for SHC peak picking (default: 1.25)
‘f0_double’- pitch doubling decision threshold (default: 150 Hz)
‘f0_half’ - pitch halving decision threshold (default: 150 Hz)
‘dp5_k1’ - weight used in dynamic program (default: 11)
‘dec_factor’ - factor for signal resampling (default: 1)
‘nccf_thresh1’ - threshold for considering a peak in NCCF (Normalized Cross Correlation Function) (default: 0.3)
‘nccf_thresh2’ - threshold for terminating search in NCCF (default: 0.9)
‘nccf_maxcands’ - maximum number of candidates found (default: 3)
‘nccf_pwidth’ - window width in NCCF peak picking (default: 5)
‘merit_boost’ - boost merit (default. 0.20)
‘merit_pivot’ - merit assigned to unvoiced candidates in definitely unvoiced frames (default: 0.99)
‘merit_extra’ - merit assigned to extra candidates in reducing pitch doubling/halving errors (default: 0.4)
‘median_value’ - order of medial filter (default: 7)
‘dp_w1’ - DP (Dynamic Programming) weight factor for voiced-voiced transitions (default: 0.15)
‘dp_w2’ - DP weight factor for voiced-unvoiced or unvoiced-voiced transitions (default: 0.5)
‘dp_w3’ - DP weight factor of unvoiced-unvoiced transitions (default: 0.1)
‘dp_w4’ - Weight factor for local costs (default: 0.9)
Exclusive from pYAAPT:
This extra parameter had to be added in order to fix a bug in the original code. More information about it here.
‘spec_pitch_min_std’ - Weight factor that sets a minimum spectral pitch standard deviation,which is calculated as min_std = pitch_avg*spec_pitch_min_std (default: 0.05, i.e. 5% of the average spectral pitch).
EXAMPLES:
Example 1 - extract the pitch track from a signal using the default configurations:
import amfm_decompy.pYAAPT as pYAAPT
import amfm_decompy.basic_tools as basic
signal = basic.SignalObj('path_to_sample.wav')
pitch = pYAAPT.yaapt(signal)
Example 2 - extract the pitch track from a signal with the minimum pitch set to 150 Hz, the frame length to 15 ms and the frame jump to 5 ms:
import amfm_decompy.pYAAPT as pYAAPT
import amfm_decompy.basic_tools as basic
signal = basic.SignalObj('path_to_sample.wav')
pitch = pYAAPT.yaapt(signal, **{'f0_min' : 150.0, 'frame_length' : 15.0, 'frame_space' : 5.0})
Classes¶
PitchObj Class¶
The PitchObj Class stores the extracted pitch and all the parameters related to it. A pitch object is necessary for the QHM algorithms. However, the pitch class structure was built in a way that it can be used by any other pitch tracker, not only the YAAPT.
USAGE:
- amfm_decompy.pYAAPT.PitchObj(frame_size, frame_jump[, nfft=8192])¶
- Parameters:
frame_size (int) – analysis frame length.
frame_jump (int) – distance between the center of a extracting frame and the center of its adjacent neighbours.
nfft (int) – FFT length.
- Return type:
pitch object.
PITCH CLASS VARIABLES:¶
These variables not related with the YAAPT algorithm itself, but with a post-processing where the data is smoothed and halving/doubling errors corrected.
- PitchObj.PITCH_HALF¶
This variable is a flag. When its value is equal to 1, the halving detector set the half pitch values to 0. If PITCH_HALF is equal to 2, the half pitch values are multiplied by 2. For other PITCH_HALF values, the halving detector is not employed (default: 0).
- PitchObj.PITCH_HALF_SENS¶
Set the halving detector sensibility. A pitch sample is considered half valued if it is not zero and lower than:
mean(pitch) - PITCH_HALF_SENS*std(pitch)
(default: 2.9).
- PitchObj.PITCH_DOUBLE¶
This variable is a flag. When its value is equal to 1, the doubling detector set the double pitch values to 0. If PITCH_DOUBLE is equal to 2, the double pitch values are divided by 2. For other PITCH_DOUBLE values, the doubling detector is not employed (default: 0).
- PitchObj.PITCH_DOUBLE_SENS¶
Set the doubling detector sensibility. A pitch sample is considered double valued if it is not zero and higher than:
mean(pitch) + PITCH_DOUBLE_SENS*std(pitch)
(default: 2.9).
- PitchObj.SMOOTH_FACTOR¶
Determines the median filter length used to smooth the interpolated pitch values (default: 5). [1]
- PitchObj.SMOOTH¶
This variable is a flag. When its value is not equal to 0, the interpolated pitch is smoothed by a median filter (default: 5). [1]
- PitchObj.PTCH_TYP¶
If there are less than 2 voiced frames in the file, the PTCH_TYP value is used in the interpolation (default: 100 Hz). [1]
Footnotes
EXAMPLE:
Example 1 - the pitch is extracted from sample.wav with different smoothing and interpolation configurations:
import amfm_decompy.pYAAPT as pYAAPT
import amfm_decompy.basic_tools as basic
signal = basic.SignalObj('path_to_sample.wav')
pYAAPT.PitchObj.PITCH_DOUBLE = 2 # set new values
pYAAPT.PitchObj.PITCH_HALF = 2
pYAAPT.PitchObj.SMOOTH_FACTOR = 3
pitch = pYAAPT.yaapt(signal) # calculate the pitch track
PITCH OBJECT ATTRIBUTES:¶
- PitchObj.nfft¶
Length in samples from the FFT used by the pitch tracker. It is set during the object’s initialization.
- PitchObj.frame_size¶
Length in samples from the frames used by the pitch tracker. It is set during the object’s initialization.
- PitchObj.frame_jump¶
Distance in samples between the center of a extracting frame and the center of its adjacent neighbours. It is set during the object’s initialization.
- PitchObj.noverlap¶
It’s the difference between the frame size and the frame jump. Represents the number of samples that two adjacent frames share in common, i.e, how much they overlap each other. It is set during the object’s initialization.
- PitchObj.mean_energy¶
Signal’s low frequency band mean energy. It is set by the PitchObj.set_energy method.
- PitchObj.energy¶
Array that contains the low frequency band energy from each frame, normalized by PitchObj.mean_energy. It is set by the PitchObj.set_energy method.
- PitchObj.vuv¶
Boolean vector that indicates if each speech frame was classified as voiced (represented as ‘True’) or unvoiced (represented as ‘False’). It is set by the PitchObj.set_energy method.
- PitchObj.frames_pos¶
A numpy array that contains the temporal location of the center of each extraction frame, which is also referred as time stamp. It is set by the PitchObj.set_frame_pos method. The locations are given in sample domain, so their values in time domain are calculated as:
import amfm_decompy.pYAAPT as pYAAPT import amfm_decompy.basic_tools as basic signal = basic.SignalObj('path_to_sample.wav') pitch = pYAAPT.yaapt(signal) time_stamp_in_seconds = pitch.frame_pos/signal.fs
- PitchObj.nframes¶
Number of frames. It is set by the PitchObj.set_frame_pos method.
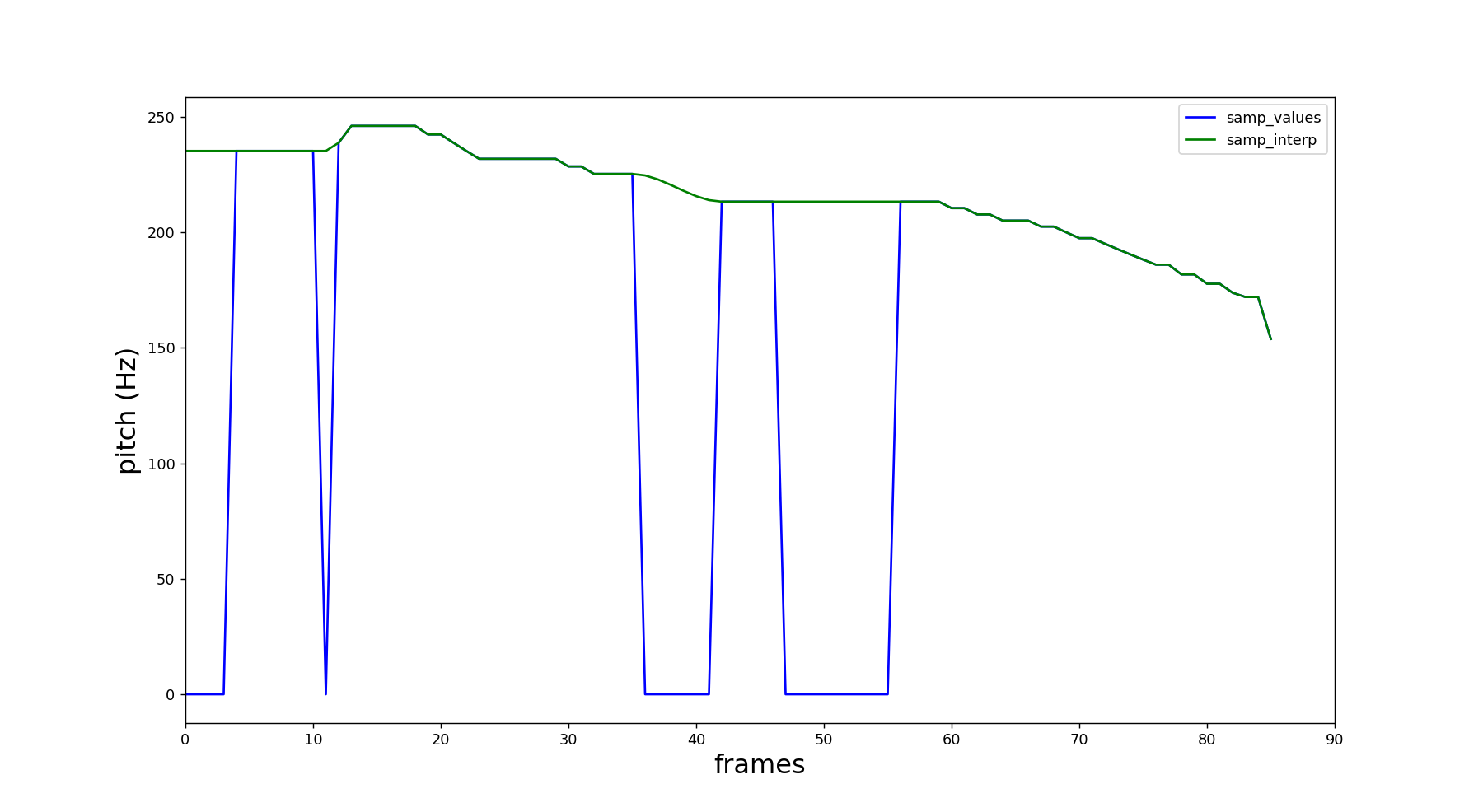
- PitchObj.samp_values¶
- PitchObj.samp_interp¶
Both arrays contain the pitch values from each of the nframes. The only difference is that, in PitchObj.samp_interp the unvoiced segments are replaced by the interpolation from the adjacent voiced segments edges. This provides a non-zero version from the pitch track, which can be necessary for some applications.
Example:
import amfm_decompy.pYAAPT as pYAAPT import amfm_decompy.basic_tools as basic from matplotlib import pyplot as plt signal = basic.SignalObj('path_to_sample.wav') pitch = pYAAPT.yaapt(signal) plt.plot(pitch.samp_values, label='samp_values', color='blue') plt.plot(pitch.samp_interp, label='samp_interp', color='green') plt.xlabel('frames', fontsize=18) plt.ylabel('pitch (Hz)', fontsize=18) plt.legend(loc='upper right') axes = plt.gca() axes.set_xlim([0,90]) plt.show()
The output is presented below:
Both attributes are set by the PitchObj.set_values method.
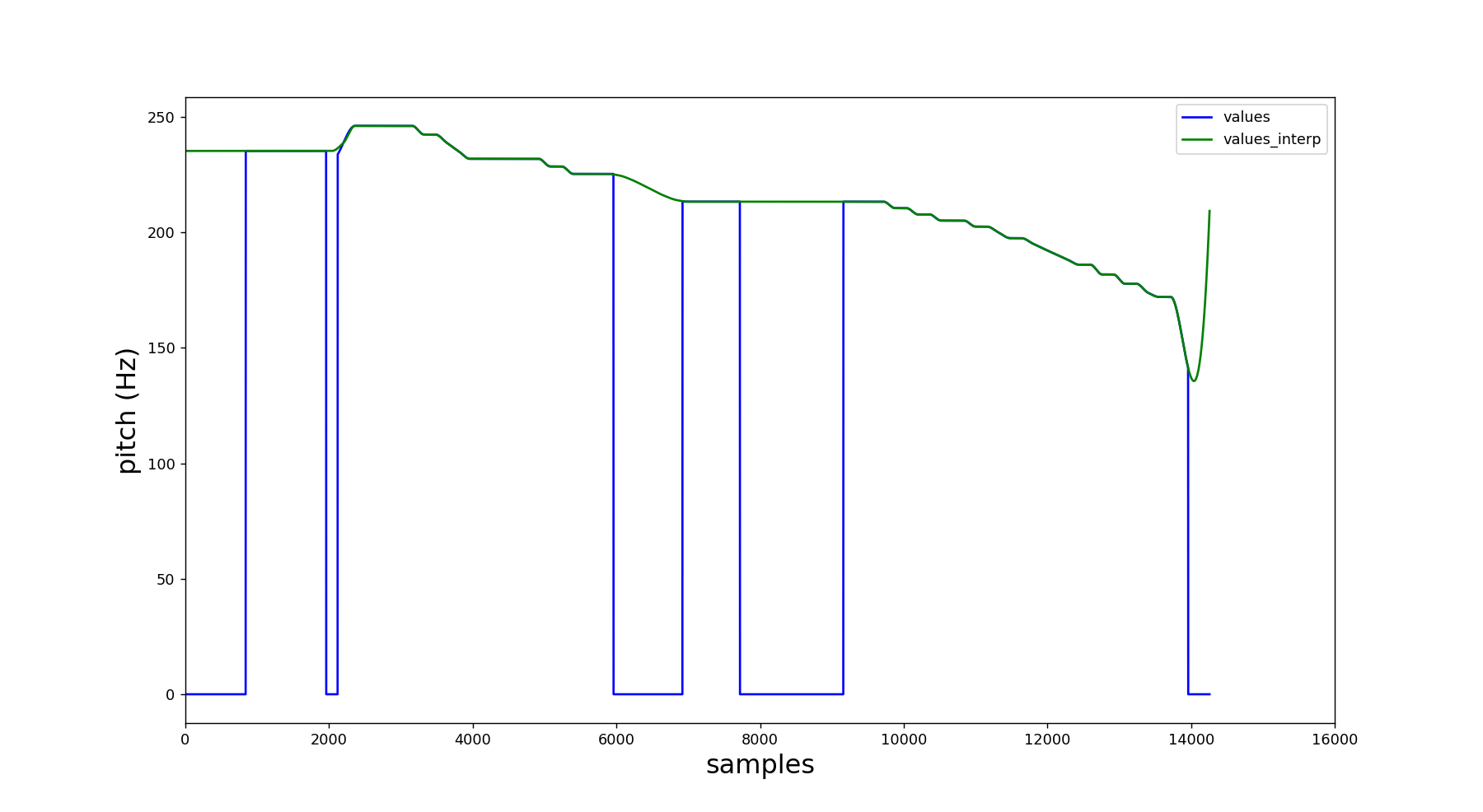
- PitchObj.values¶
- PitchObj.values_interp¶
PitchObj.values and PitchObj.values_interp are the upsampled versions from PitchObj.samp_values and PitchObj.samp_interp respectively. Therefore, their length is equal to the original file length (for more information, check the PitchObj.upsample() method).
Example:
import amfm_decompy.pYAAPT as pYAAPT import amfm_decompy.basic_tools as basic from matplotlib import pyplot as plt signal = basic.SignalObj('path_to_sample.wav') pitch = pYAAPT.yaapt(signal) plt.plot(pitch.values, label='samp_values', color='blue') plt.plot(pitch.values_interp, label='samp_interp', color='green') plt.xlabel('samples', fontsize=18) plt.ylabel('pitch (Hz)', fontsize=18) plt.legend(loc='upper right') axes = plt.gca() axes.set_xlim([0,16000]) plt.show()
The output is presented below:
Both attributes are set by the PitchObj.set_values method.
- PitchObj.edges¶
A list that contains the index where occur the transitions between unvoiced-voiced and voiced-unvoiced in PitchObj.values. It is set by the PitchObj.set_values method, which employs internally the PitchObj.edges_finder method.
PITCH OBJECT METHODS:¶
- PitchObj.set_energy(energy, threshold)¶
- Parameters:
energy (numpy array) – contains the low frequency energy for each frame.
threshold – normalized threshold.
Set the normalized low frequency energy by taking the input array and dividing it by its mean value. Normalized values above the threshold are considered voiced frames, while the ones below it are unvoiced frames.
- PitchObj.set_frames_pos(frames_pos)¶
- Parameters:
frames_pos – index with the sample positions.
Set the position from the center of the extraction frames.
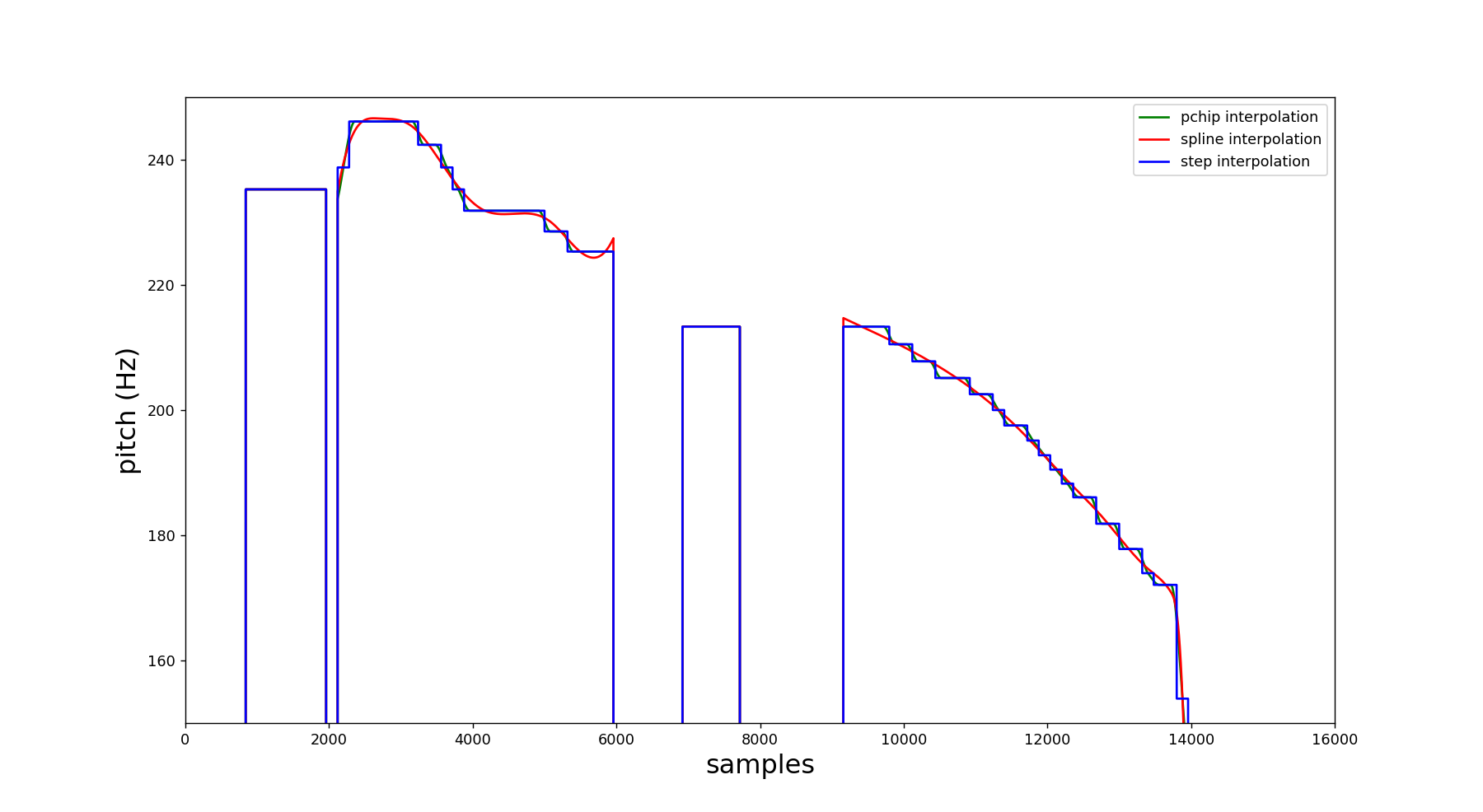
- PitchObj.set_values(samp_values, file_size[, interp_tech='spline'])¶
- Parameters:
samp_values (numpy array) – pitch value for each frame.
file_size (int) – length of the speech signal.
interp_tech (string) – interpolation method employed to upsample the data. Can be ‘pchip’ (default), ‘spline’ and ‘step’.
Set the pitch values and also calculates its interpolated version (for more information, check the PitchObj.samp_values and PitchObj.samp_interp attributes). A post-process is employed then using the PitchObj class attributes. After that, both arrays are upsampled, so that the output arrays have the same length as the original speech signal. In this process, a second interpolation is necessary. The interpolation technique employed is indicated by the parameter interp_tech.
Example:
import amfm_decompy.pYAAPT as pYAAPT import amfm_decompy.basic_tools as basic from matplotlib import pyplot as plt signal = basic.SignalObj('path_to_sample.wav') pitch = pYAAPT.yaapt(signal) plt.plot(pitch.values, label='pchip interpolation', color='green') pitch.set_values(pitch.samp_values, len(pitch.values), interp_tech='spline') plt.plot(pitch.values, label='spline interpolation', color='red') pitch.set_values(pitch.samp_values, len(pitch.values), interp_tech='step') plt.plot(pitch.values, label='step interpolation', color='blue') plt.xlabel('samples', fontsize=18) plt.ylabel('pitch (Hz)', fontsize=18) plt.legend(loc='upper right') axes = plt.gca() axes.set_xlim([0,16000]) axes.set_ylim([150,250]) plt.show()
The output is presented below:
- PitchObj.edges_finder(values)¶
- Parameters:
values (numpy array) – contains the low frequency energy for each frame.
- Return type:
list.
Returns the index of the samples where occur the transitions between unvoiced-voiced and voiced-unvoiced.
BandpassFilter Class¶
Creates a bandpass filter necessary for the YAAPT algorithm.
USAGE:
- amfm_decompy.pYAAPT.BandpassFilter(fs, parameters)¶
- Parameters:
fs (float) – signal’s fundamental frequency
parameters (dictionary) – contains the parameters options from the YAAPT algorithm.
- Return type:
bandpass filter object.
BANDPASS FILTER ATTRIBUTES:¶
- BandpassFilter.b¶
Bandpass filter zeros coefficients. It is set during the object’s initialization.
- BandpassFilter.a¶
Bandpass filter poles coefficients. It is set during the object’s initialization.
- BandpassFilter.dec_factor¶
Decimation factor used for downsampling the data. It is set during the object’s initialization.
Differences between pYAAPT and the original YAAPT¶
As stated before, the pYAAPT was conceived as a port of the original Matlab YAAPT package. However, with the evolution of the YAAPT and also with the constant feedback from pYAAPT users, there are currently a few important differences between both codes:
YAAPT 4.0 processing speed¶
The version 4.0 from the YAAPT came with an additional feature that allows the user to “skip” the spectral pitch tracking, or alternatively, skip the time domain pitch tracking. Although I understand why the feature was implemented (Matlab has some limitations in terms of optimizing the code performance), personally I consider this addition a bit questionable.
The strong point of the YAAPT is its robustness. And by personal experience, I would say that most of my speech processing projects relied on the efficiency of the pitch tracker. Thus, sacrificing the robustness of the algorithm can cause a snowball effect that could eventually compromise an entire project.
Therefore, until the present moment the speed feature is not available at pYAAPT. Specially because Python still has some better speeding options to be explored, like numba or CUDA. Eventually I might add this speed parameter to some future major release, it does not require an extensive code refactoring anyway.
But since that this feature is a bit counter-productive, I do not see it currently as priority.
spec_pitch_min_std parameter¶
In the function tm_trk.m from the original YAAPT code, the spectral pitch standard deviation (pStd) is employed to calculate the frequency threshold (freq_threshold) variable, which is later used to refine the merit of the pitch candidates.
However, in some corner cases it might happen that all spectral pitch values are the same, which results in a standard deviation equal to zero. And since that the freq_threshold is employed as the denominator of a fraction, this will lead to a division by 0, which will consequently crash the algorithm. This issue was reported in real-time applications using the pYAAPT.
Since that this bug is also present in the original Matlab code, a custom solution had to be developed. Thus, the most reasonable approach was to use a percentage of the average spectral pitch. This percentage was named spec_pitch_min_std, which has default value of 0.05. Therefore, when the standard deviation of the spectral pitch is lower than 5% of its mean value, this fraction of the average pitch is employed instead of the standard deviation.